 authentication.md
authentication.md- clustering.md
- configuration.md
- container.md
- etcd-sample-grafana.png
- etcd3_alert.rules
- etcd3_alert.rules.yml
- failures.md
- gateway.md
- grafana.json
- grpc_proxy.md
- hardware.md
- maintenance.md
- monitoring.md
- performance.md
- recovery.md
- runtime-configuration.md
- runtime-reconf-design.md
- security.md
- supported-platform.md
- v2-migration.md
- versioning.md
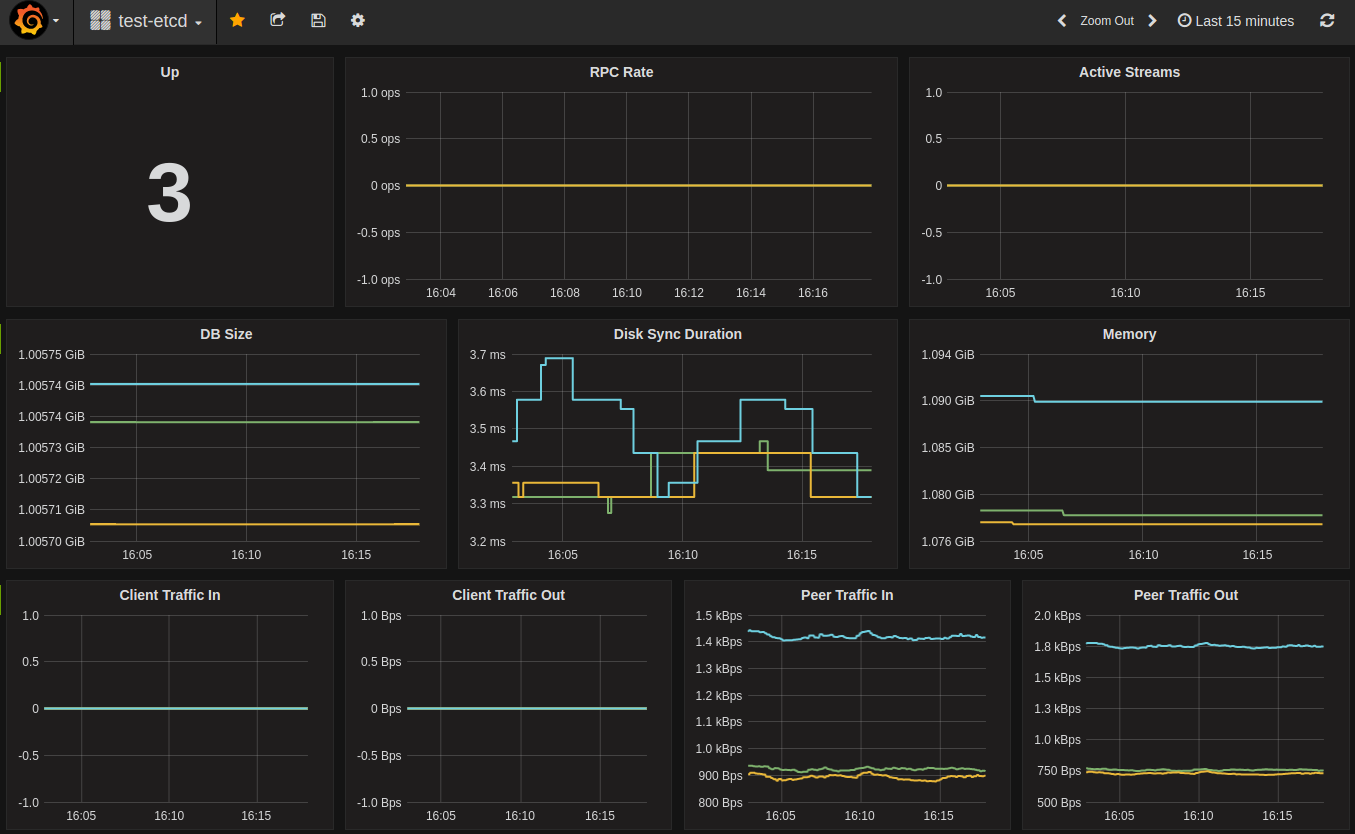 etcd-sample-grafana.png
etcd-sample-grafana.pngTable of Contents
etcd is designed to withstand machine failures. An etcd cluster automatically recovers from temporary failures (e.g., machine reboots) and tolerates up to (N-1)/2 permanent failures for a cluster of N members. When a member permanently fails, whether due to hardware failure or disk corruption, it loses access to the cluster. If the cluster permanently loses more than (N-1)/2 members then it disastrously fails, irrevocably losing quorum. Once quorum is lost, the cluster cannot reach consensus and therefore cannot continue accepting updates.
To recover from disastrous failure, etcd v3 provides snapshot and restore facilities to recreate the cluster without v3 key data loss. To recover v2 keys, refer to the v2 admin guide.
Snapshotting the keyspace
Recovering a cluster first needs a snapshot of the keyspace from an etcd member. A snapshot may either be taken from a live member with the etcdctl snapshot save command or by copying the member/snap/db file from an etcd data directory. For example, the following command snapshots the keyspace served by $ENDPOINT to the file snapshot.db:
$ ETCDCTL_API=3 etcdctl --endpoints $ENDPOINT snapshot save snapshot.db
Restoring a cluster
To restore a cluster, all that is needed is a single snapshot "db" file. A cluster restore with etcdctl snapshot restore creates new etcd data directories; all members should restore using the same snapshot. Restoring overwrites some snapshot metadata (specifically, the member ID and cluster ID); the member loses its former identity. This metadata overwrite prevents the new member from inadvertently joining an existing cluster. Therefore in order to start a cluster from a snapshot, the restore must start a new logical cluster.
Snapshot integrity may be optionally verified at restore time. If the snapshot is taken with etcdctl snapshot save, it will have an integrity hash that is checked by etcdctl snapshot restore. If the snapshot is copied from the data directory, there is no integrity hash and it will only restore by using --skip-hash-check.
A restore initializes a new member of a new cluster, with a fresh cluster configuration using etcd's cluster configuration flags, but preserves the contents of the etcd keyspace. Continuing from the previous example, the following creates new etcd data directories (m1.etcd, m2.etcd, m3.etcd) for a three member cluster:
$ ETCDCTL_API=3 etcdctl snapshot restore snapshot.db \
--name m1 \
--initial-cluster m1=http://host1:2380,m2=http://host2:2380,m3=http://host3:2380 \
--initial-cluster-token etcd-cluster-1 \
--initial-advertise-peer-urls http://host1:2380
$ ETCDCTL_API=3 etcdctl snapshot restore snapshot.db \
--name m2 \
--initial-cluster m1=http://host1:2380,m2=http://host2:2380,m3=http://host3:2380 \
--initial-cluster-token etcd-cluster-1 \
--initial-advertise-peer-urls http://host2:2380
$ ETCDCTL_API=3 etcdctl snapshot restore snapshot.db \
--name m3 \
--initial-cluster m1=http://host1:2380,m2=http://host2:2380,m3=http://host3:2380 \
--initial-cluster-token etcd-cluster-1 \
--initial-advertise-peer-urls http://host3:2380
Next, start etcd with the new data directories:
$ etcd \
--name m1 \
--listen-client-urls http://host1:2379 \
--advertise-client-urls http://host1:2379 \
--listen-peer-urls http://host1:2380 &
$ etcd \
--name m2 \
--listen-client-urls http://host2:2379 \
--advertise-client-urls http://host2:2379 \
--listen-peer-urls http://host2:2380 &
$ etcd \
--name m3 \
--listen-client-urls http://host3:2379 \
--advertise-client-urls http://host3:2379 \
--listen-peer-urls http://host3:2380 &
Now the restored etcd cluster should be available and serving the keyspace given by the snapshot.
Restoring a cluster from membership mis-reconfiguration with wrong URLs
Previously, etcd panics on membership mis-reconfiguration with wrong URLs (v3.2.15 or later returns error early in client-side before etcd server panic).
Recommended way is restore from snapshot. --force-new-cluster can be used to overwrite cluster membership while keeping existing application data, but is strongly discouraged because it will panic if other members from previous cluster are still alive. Make sure to save snapshot periodically.