 authentication.md
authentication.md- clustering.md
- configuration.md
- container.md
- etcd-sample-grafana.png
- etcd3_alert.rules
- etcd3_alert.rules.yml
- failures.md
- gateway.md
- grafana.json
- grpc_proxy.md
- hardware.md
- maintenance.md
- monitoring.md
- performance.md
- recovery.md
- runtime-configuration.md
- runtime-reconf-design.md
- security.md
- supported-platform.md
- v2-migration.md
- versioning.md
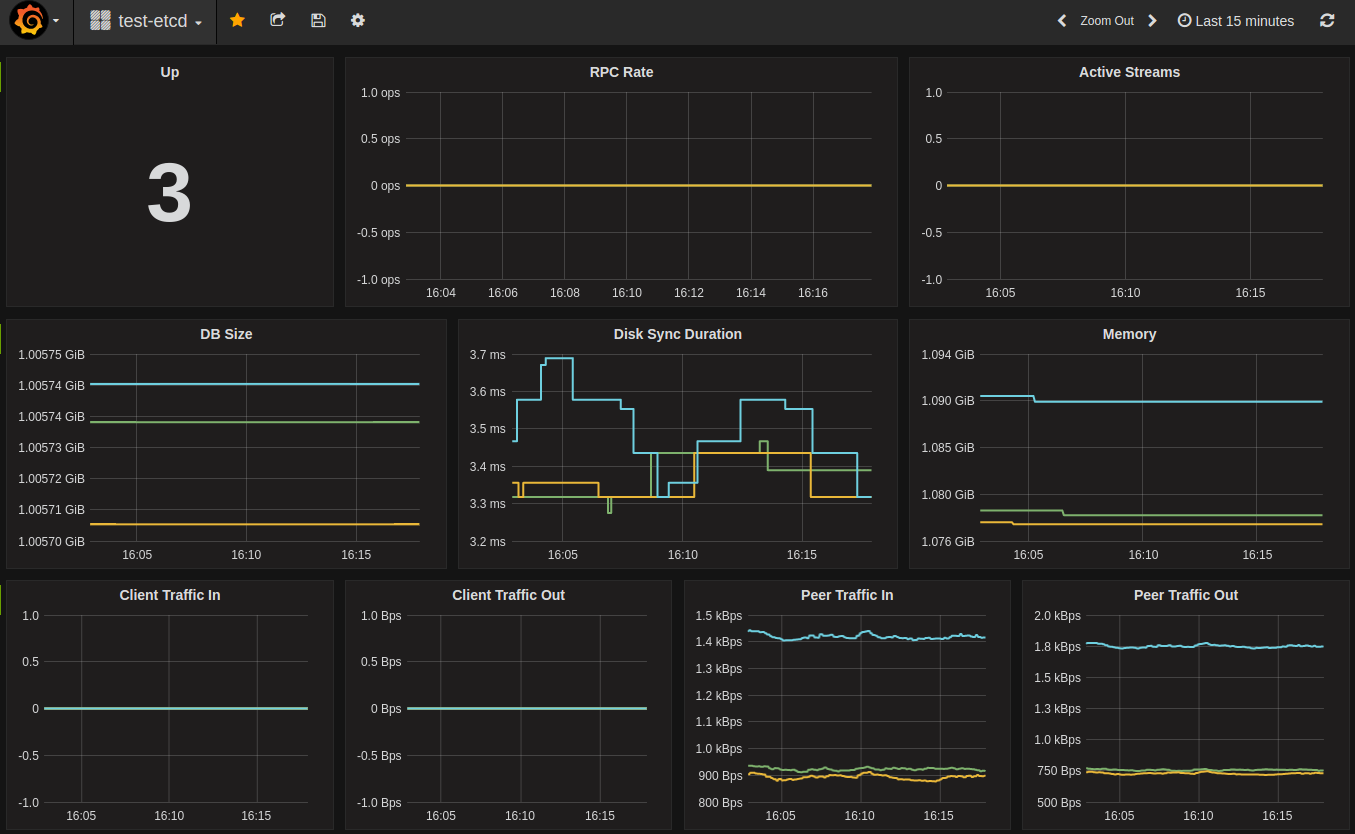 etcd-sample-grafana.png
etcd-sample-grafana.pngTable of Contents
Failures are common in a large deployment of machines. A machine fails when its hardware or software malfunctions. Multiple machines fail together when there are power failures or network issues. Multiple kinds of failures can also happen at once; it is almost impossible to enumerate all possible failure cases.
In this section, we catalog kinds of failures and discuss how etcd is designed to tolerate these failures. Most users, if not all, can map a particular failure into one kind of failure. To prepare for rare or unrecoverable failures, always back up the etcd cluster.
Minor followers failure
When fewer than half of the followers fail, the etcd cluster can still accept requests and make progress without any major disruption. For example, two follower failures will not affect a five member etcd cluster’s operation. However, clients will lose connectivity to the failed members. Client libraries should hide these interruptions from users for read requests by automatically reconnecting to other members. Operators should expect the system load on the other members to increase due to the reconnections.
Leader failure
When a leader fails, the etcd cluster automatically elects a new leader. The election does not happen instantly once the leader fails. It takes about an election timeout to elect a new leader since the failure detection model is timeout based.
During the leader election the cluster cannot process any writes. Write requests sent during the election are queued for processing until a new leader is elected.
Writes already sent to the old leader but not yet committed may be lost. The new leader has the power to rewrite any uncommitted entries from the previous leader. From the user perspective, some write requests might time out after a new leader election. However, no committed writes are ever lost.
The new leader extends timeouts automatically for all leases. This mechanism ensures a lease will not expire before the granted TTL even if it was granted by the old leader.
Majority failure
When the majority members of the cluster fail, the etcd cluster fails and cannot accept more writes.
The etcd cluster can only recover from a majority failure once the majority of members become available. If a majority of members cannot come back online, then the operator must start disaster recovery to recover the cluster.
Once a majority of members works, the etcd cluster elects a new leader automatically and returns to a healthy state. The new leader extends timeouts automatically for all leases. This mechanism ensures no lease expires due to server side unavailability.
Network partition
A network partition is similar to a minor followers failure or a leader failure. A network partition divides the etcd cluster into two parts; one with a member majority and the other with a member minority. The majority side becomes the available cluster and the minority side is unavailable; there is no “split-brain” in etcd.
If the leader is on the majority side, then from the majority point of view the failure is a minority follower failure. If the leader is on the minority side, then it is a leader failure. The leader on the minority side steps down and the majority side elects a new leader.
Once the network partition clears, the minority side automatically recognizes the leader from the majority side and recovers its state.
Failure during bootstrapping
A cluster bootstrap is only successful if all required members successfully start. If any failure happens during bootstrapping, remove the data directories on all members and re-bootstrap the cluster with a new cluster-token or new discovery token.
Of course, it is possible to recover a failed bootstrapped cluster like recovering a running cluster. However, it almost always takes more time and resources to recover that cluster than bootstrapping a new one, since there is no data to recover.