Table of Contents
上一节我们说完了 GPM 结构体,这一讲,我们来研究 Go sheduler 结构体,以及整个调度器的初始化过程。
Go scheduler 在源码中的结构体为 schedt,保存调度器的状态信息、全局的可运行 G 队列等。源码如下:
// 保存调度器的信息
type schedt struct {
// accessed atomically. keep at top to ensure alignment on 32-bit systems.
// 需以原子访问访问。
// 保持在 struct 顶部,以使其在 32 位系统上可以对齐
goidgen uint64
lastpoll uint64
lock mutex
// 由空闲的工作线程组成的链表
midle muintptr // idle m's waiting for work
// 空闲的工作线程数量
nmidle int32 // number of idle m's waiting for work
// 空闲的且被 lock 的 m 计数
nmidlelocked int32 // number of locked m's waiting for work
// 已经创建的工作线程数量
mcount int32 // number of m's that have been created
// 表示最多所能创建的工作线程数量
maxmcount int32 // maximum number of m's allowed (or die)
// goroutine 的数量,自动更新
ngsys uint32 // number of system goroutines; updated atomically
// 由空闲的 p 结构体对象组成的链表
pidle puintptr // idle p's
// 空闲的 p 结构体对象的数量
npidle uint32
nmspinning uint32 // See "Worker thread parking/unparking" comment in proc.go.
// Global runnable queue.
// 全局可运行的 G队列
runqhead guintptr // 队列头
runqtail guintptr // 队列尾
runqsize int32 // 元素数量
// Global cache of dead G's.
// dead G 的全局缓存
// 已退出的 goroutine 对象,缓存下来
// 避免每次创建 goroutine 时都重新分配内存
gflock mutex
gfreeStack *g
gfreeNoStack *g
// 空闲 g 的数量
ngfree int32
// Central cache of sudog structs.
// sudog 结构的集中缓存
sudoglock mutex
sudogcache *sudog
// Central pool of available defer structs of different sizes.
// 不同大小的可用的 defer struct 的集中缓存池
deferlock mutex
deferpool [5]*_defer
gcwaiting uint32 // gc is waiting to run
stopwait int32
stopnote note
sysmonwait uint32
sysmonnote note
// safepointFn should be called on each P at the next GC
// safepoint if p.runSafePointFn is set.
safePointFn func(*p)
safePointWait int32
safePointNote note
profilehz int32 // cpu profiling rate
// 上次修改 gomaxprocs 的纳秒时间
procresizetime int64 // nanotime() of last change to gomaxprocs
totaltime int64 // ∫gomaxprocs dt up to procresizetime
}
在程序运行过程中,schedt 对象只有一份实体,它维护了调度器的所有信息。
在 proc.go 和 runtime2.go 文件中,有一些很重要全局的变量,我们先列出来:
// 所有 g 的长度
allglen uintptr
// 保存所有的 g
allgs []*g
// 保存所有的 m
allm *m
// 保存所有的 p,_MaxGomaxprocs = 1024
allp [_MaxGomaxprocs + 1]*p
// p 的最大值,默认等于 ncpu
gomaxprocs int32
// 程序启动时,会调用 osinit 函数获得此值
ncpu int32
// 调度器结构体对象,记录了调度器的工作状态
sched schedt
// 代表进程的主线程
m0 m
// m0 的 g0,即 m0.g0 = &g0
g0 g
在程序初始化时,这些全局变量都会被初始化为零值:指针被初始化为 nil 指针,切片被初始化为 nil 切片,int 被初始化为 0,结构体的所有成员变量按其类型被初始化为对应的零值。
因此程序刚启动时 allgs,allm 和allp 都不包含任何 g,m 和 p。
不仅是 Go 程序,系统加载可执行文件大概都会经过这几个阶段:
- 从磁盘上读取可执行文件,加载到内存
- 创建进程和主线程
- 为主线程分配栈空间
- 把由用户在命令行输入的参数拷贝到主线程的栈
- 把主线程放入操作系统的运行队列等待被调度
上面这段描述,来自公众号“ go语言核心编程技术”的调度系列教程。
我们从一个 Hello World 的例子来回顾一下 Go 程序初始化的过程:
package main
import "fmt"
func main() {
fmt.Println("hello world")
}
在项目根目录下执行:
go build -gcflags "-N -l" -o hello src/main.go
-gcflags "-N -l" 是为了关闭编译器优化和函数内联,防止后面在设置断点的时候找不到相对应的代码位置。
得到了可执行文件 hello,执行:
[qcrao@qcrao hello-world]$ gdb hello
进入 gdb 调试模式,执行 info files,得到可执行文件的文件头,列出了各种段:

同时,我们也得到了入口地址:0x450e20。
(gdb) b *0x450e20
Breakpoint 1 at 0x450e20: file /usr/local/go/src/runtime/rt0_linux_amd64.s, line 8.
这就是 Go 程序的入口地址,我是在 linux 上运行的,所以入口文件为 src/runtime/rt0_linux_amd64.s,runtime 目录下有各种不同名称的程序入口文件,支持各种操作系统和架构,代码为:
TEXT _rt0_amd64_linux(SB),NOSPLIT,$-8
LEAQ 8(SP), SI // argv
MOVQ 0(SP), DI // argc
MOVQ $main(SB), AX
JMP AX
主要是把 argc,argv 从内存拉到了寄存器。这里 LEAQ 是计算内存地址,然后把内存地址本身放进寄存器里,也就是把 argv 的地址放到了 SI 寄存器中。最后跳转到:
TEXT main(SB),NOSPLIT,$-8
MOVQ $runtime·rt0_go(SB), AX
JMP AX
继续跳转到 runtime·rt0_go(SB),完成 go 启动时所有的初始化工作。位于 /usr/local/go/src/runtime/asm_amd64.s,代码:
TEXT runtime·rt0_go(SB),NOSPLIT,$0
// copy arguments forward on an even stack
MOVQ DI, AX // argc
MOVQ SI, BX // argv
SUBQ $(4*8+7), SP // 2args 2auto
// 调整栈顶寄存器使其按 16 字节对齐
ANDQ $~15, SP
// argc 放在 SP+16 字节处
MOVQ AX, 16(SP)
// argv 放在 SP+24 字节处
MOVQ BX, 24(SP)
// create istack out of the given (operating system) stack.
// _cgo_init may update stackguard.
// 给 g0 分配栈空间
// 把 g0 的地址存入 DI
MOVQ $runtime·g0(SB), DI
// BX = SP - 64*1024 + 104
LEAQ (-64*1024+104)(SP), BX
// g0.stackguard0 = SP - 64*1024 + 104
MOVQ BX, g_stackguard0(DI)
// g0.stackguard1 = SP - 64*1024 + 104
MOVQ BX, g_stackguard1(DI)
// g0.stack.lo = SP - 64*1024 + 104
MOVQ BX, (g_stack+stack_lo)(DI)
// g0.stack.hi = SP
MOVQ SP, (g_stack+stack_hi)(DI)
// ……………………
// 省略了很多检测 CPU 信息的代码
// ……………………
// 初始化 m 的 tls
// DI = &m0.tls,取 m0 的 tls 成员的地址到 DI 寄存器
LEAQ runtime·m0+m_tls(SB), DI
// 调用 settls 设置线程本地存储,settls 函数的参数在 DI 寄存器中
// 之后,可通过 fs 段寄存器找到 m.tls
CALL runtime·settls(SB)
// store through it, to make sure it works
// 获取 fs 段基址并放入 BX 寄存器,其实就是 m0.tls[1] 的地址,get_tls 的代码由编译器生成
get_tls(BX)
MOVQ $0x123, g(BX)
MOVQ runtime·m0+m_tls(SB), AX
CMPQ AX, $0x123
JEQ 2(PC)
MOVL AX, 0 // abort
ok:
// set the per-goroutine and per-mach "registers"
// 获取 fs 段基址到 BX 寄存器
get_tls(BX)
// 将 g0 的地址存储到 CX,CX = &g0
LEAQ runtime·g0(SB), CX
// 把 g0 的地址保存在线程本地存储里面,也就是 m0.tls[0]=&g0
MOVQ CX, g(BX)
// 将 m0 的地址存储到 AX,AX = &m0
LEAQ runtime·m0(SB), AX
// save m->g0 = g0
// m0.g0 = &g0
MOVQ CX, m_g0(AX)
// save m0 to g0->m
// g0.m = &m0
MOVQ AX, g_m(CX)
CLD // convention is D is always left cleared
CALL runtime·check(SB)
MOVL 16(SP), AX // copy argc
MOVL AX, 0(SP)
MOVQ 24(SP), AX // copy argv
MOVQ AX, 8(SP)
CALL runtime·args(SB)
// 初始化系统核心数
CALL runtime·osinit(SB)
// 调度器初始化
CALL runtime·schedinit(SB)
// create a new goroutine to start program
MOVQ $runtime·mainPC(SB), AX // entry
// newproc 的第二个参数入栈,也就是新的 goroutine 需要执行的函数
// AX = &funcval{runtime·main},
PUSHQ AX
// newproc 的第一个参数入栈,该参数表示 runtime.main 函数需要的参数大小,
// 因为 runtime.main 没有参数,所以这里是 0
PUSHQ $0 // arg size
// 创建 main goroutine
CALL runtime·newproc(SB)
POPQ AX
POPQ AX
// start this M
// 主线程进入调度循环,运行刚刚创建的 goroutine
CALL runtime·mstart(SB)
// 永远不会返回,万一返回了,crash 掉
MOVL $0xf1, 0xf1 // crash
RET
这段代码完成之后,整个 Go 程序就可以跑起来了,是非常核心的代码。这一讲其实只讲到了第 80 行,也就是调度器初始化函数:
CALL runtime·schedinit(SB)
schedinit 函数返回后,调度器的相关参数都已经初始化好了,犹如盘古开天辟地,万事万物各就其位。接下来详细解释上面的汇编代码。
调整 SP
第一段代码,将 SP 调整到了一个地址是 16 的倍数的位置:
SUBQ $(4*8+7), SP // 2args 2auto
// 调整栈顶寄存器使其按 16 个字节对齐
ANDQ $~15, SP
先是将 SP 减掉 39,也就是向下移动了 39 个 Byte,再进行与运算。
15 的二进制低四位是全 1:1111,其他位都是 0;取反后,变成了 0000,高位则是全 1。这样,与 SP 进行了与运算后,低 4 位变成了全 0,高位则不变。因此 SP 继续向下移动,并且这回是在一个地址值为 16 的倍数的地方,16 字节对齐的地方。
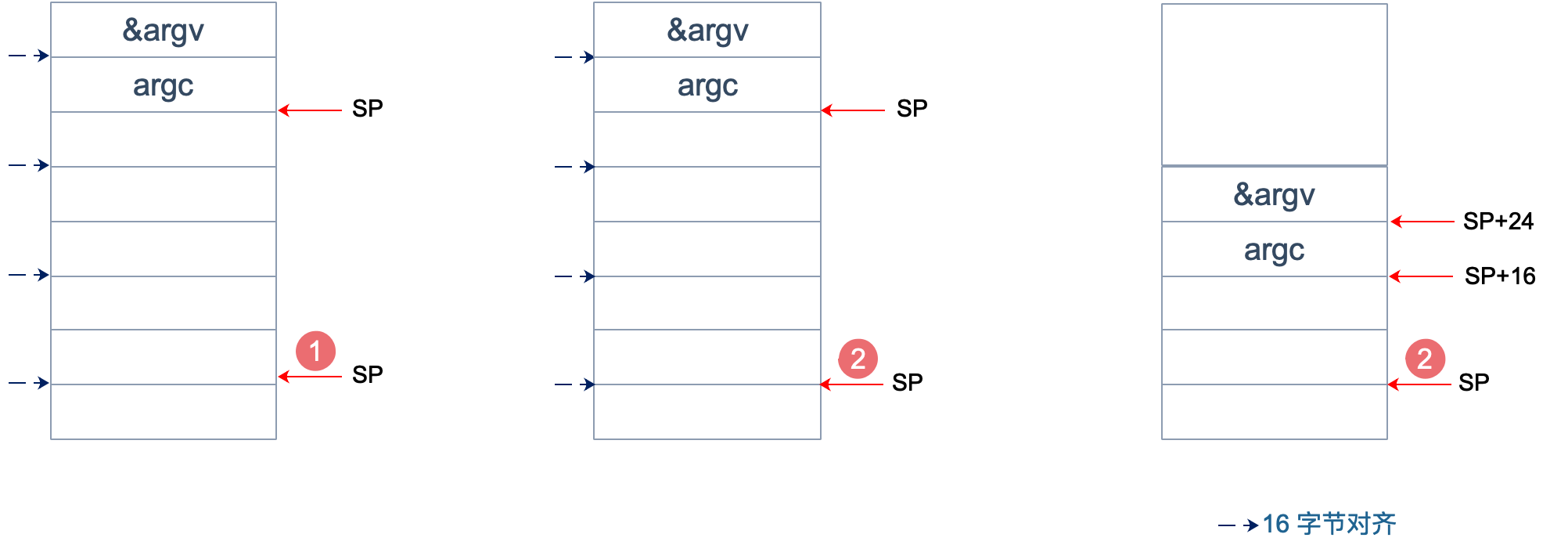
为什么要这么做?画一张图就明白了。不过先得说明一点,前面 _rt0_amd64_linux 函数里讲过,DI 里存的是 argc 的值,8 个字节,而 SI 里则存的是 argv 的地址,8 个字节。
![SP 内存对齐]](https://user-images.githubusercontent.com/7698088/64070957-8eda8f80-cca1-11e9-91c7-0b276d7769ea.png)
{kind=link}

上面两张图中,左侧用箭头标注了 16 字节对齐的位置。第一步表示向下移动 39 B,第二步表示与 ~15 相与。
存在两种情况,这也是第一步将 SP 下移的时候,多移了 7 个 Byte 的原因。第一张图里,与 ~15 相与的时候,SP 值减少了 1,第二张图则减少了 9。最后都是移位到了 16 字节对齐的位置。
两张图的共同点是 SP 与 argc 中间多出了 16 个字节的空位。这个后面应该会用到,我们接着探索。
至于为什么进行 16 个字节对齐,就比较好理解了:因为 CPU 有一组 SSE 指令,这些指令中出现的内存地址必须是 16 的倍数。
初始化 g0 栈
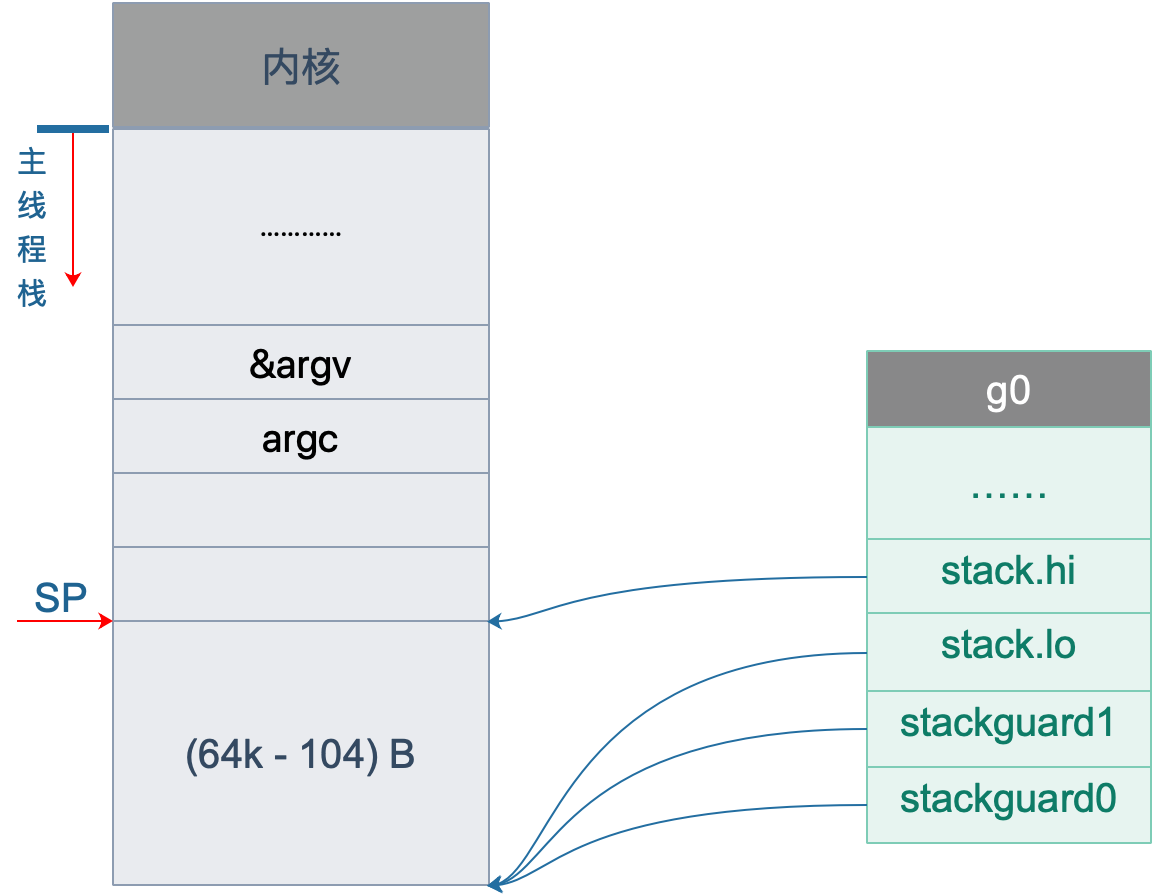
接着往后看,开始初始化 g0 的栈了。g0 栈的作用就是为运行 runtime 代码提供一个“环境”。
// 把 g0 的地址存入 DI
MOVQ $runtime·g0(SB), DI
// BX = SP - 64*1024 + 104
LEAQ (-64*1024+104)(SP), BX
// g0.stackguard0 = SP - 64*1024 + 104
MOVQ BX, g_stackguard0(DI)
// g0.stackguard1 = SP - 64*1024 + 104
MOVQ BX, g_stackguard1(DI)
// g0.stack.lo = SP - 64*1024 + 104
MOVQ BX, (g_stack+stack_lo)(DI)
// g0.stack.hi = SP
MOVQ SP, (g_stack+stack_hi)(DI)
代码 L2 把 g0 的地址存入 DI 寄存器;L4 将 SP 下移 (64K-104)B,并将地址存入 BX 寄存器;L6 将 BX 里存储的地址赋给 g0.stackguard0;L8,L10,L12 分别 将 BX 里存储的地址赋给 g0.stackguard1, g0.stack.lo, g0.stack.hi。
这部分完成之后,g0 栈空间如下图:
主线程绑定 m0
接着往下看,中间我们省略了很多检查 CPU 相关的代码,直接看主线程绑定 m0 的部分:
// 初始化 m 的 tls
// DI = &m0.tls,取 m0 的 tls 成员的地址到 DI 寄存器
LEAQ runtime·m0+m_tls(SB), DI
// 调用 settls 设置线程本地存储,settls 函数的参数在 DI 寄存器中
// 之后,可通过 fs 段寄存器找到 m.tls
CALL runtime·settls(SB)
// store through it, to make sure it works
// 获取 fs 段基地址并放入 BX 寄存器,其实就是 m0.tls[1] 的地址,get_tls 的代码由编译器生成
get_tls(BX)
MOVQ $0x123, g(BX)
MOVQ runtime·m0+m_tls(SB), AX
CMPQ AX, $0x123
JEQ 2(PC)
MOVL AX, 0 // abort
因为 m0 是全局变量,而 m0 又要绑定到工作线程才能执行。我们又知道,runtime 会启动多个工作线程,每个线程都会绑定一个 m0。而且,代码里还得保持一致,都是用 m0 来表示。这就要用到线程本地存储的知识了,也就是常说的 TLS(Thread Local Storage)。简单来说,TLS 就是线程本地的私有的全局变量。
一般而言,全局变量对进程中的多个线程同时可见。进程中的全局变量与函数内定义的静态(static)变量,是各个线程都可以访问的共享变量。一个线程修改了,其他线程就会“看见”。要想搞出一个线程私有的变量,就需要用到 TLS 技术。
如果需要在一个线程内部的各个函数调用都能访问、但其它线程不能访问的变量(被称为 static memory local to a thread,线程局部静态变量),就需要新的机制来实现。这就是 TLS。
继续来看源码,L3 将 m0.tls 地址存储到 DI 寄存器,再调用 settls 完成 tls 的设置,tls 是 m 结构体中的一个数组。
// thread-local storage (for x86 extern register)
tls [6]uintptr
设置 tls 的函数 runtime·settls(SB) 位于源码 src/runtime/sys_linux_amd64.s 处,主要内容就是通过一个系统调用将 fs 段基址设置成 m.tls[1] 的地址,而 fs 段基址又可以通过 CPU 里的寄存器 fs 来获取。
而每个线程都有自己的一组 CPU 寄存器值,操作系统在把线程调离 CPU 时会帮我们把所有寄存器中的值保存在内存中,调度线程来运行时又会从内存中把这些寄存器的值恢复到 CPU。
这样,工作线程代码就可以通过 fs 寄存器来找到 m.tls。
关于 settls 这个函数的解析可以去看阿波张的教程第 12 篇,写得很详细。
设置完 tls 之后,又来了一段验证上面 settls 是否能正常工作。如果不能,会直接 crash。
get_tls(BX)
MOVQ $0x123, g(BX)
MOVQ runtime·m0+m_tls(SB), AX
CMPQ AX, $0x123
JEQ 2(PC)
MOVL AX, 0 // abort
第一行代码,获取 tls,get_tls(BX) 的代码由编译器生成,源码中并没有看到,可以理解为将 m.tls 的地址存入 BX 寄存器。
L2 将一个数 0x123 放入 m.tls[0] 处,L3 则将 m.tls[0] 处的数据取出来放到 AX 寄存器,L4 则比较两者是否相等。如果相等,则跳过 L6 行的代码,否则执行 L6,程序 crash。
继续看代码:
// set the per-goroutine and per-mach "registers"
// 获取 fs 段基址到 BX 寄存器
get_tls(BX)
// 将 g0 的地址存储到 CX,CX = &g0
LEAQ runtime·g0(SB), CX
// 把 g0 的地址保存在线程本地存储里面,也就是 m0.tls[0]=&g0
MOVQ CX, g(BX)
// 将 m0 的地址存储到 AX,AX = &m0
LEAQ runtime·m0(SB), AX
// save m->g0 = g0
// m0.g0 = &g0
MOVQ CX, m_g0(AX)
// save m0 to g0->m
// g0.m = &m0
MOVQ AX, g_m(CX)
L3 将 m.tls 地址存入 BX;L5 将 g0 的地址存入 CX;L7 将 CX,也就是 g0 的地址存入 m.tls[0];L9 将 m0 的地址存入 AX;L13 将 g0 的地址存入 m0.g0;L16 将 m0 存入 g0.m。也就是:
tls[0] = g0
m0.g0 = &g0
g0.m = &m0
代码中寄存器前面的符号看着比较奇怪,其实它们最后会被链接器转化为偏移量。
看曹大 golang_notes 用 gobuf_sp(BX) 这个例子讲的:
这种写法在标准 plan9 汇编中只是个 symbol,没有任何偏移量的意思,但这里却用名字来代替了其偏移量,这是怎么回事呢?
实际上这是 runtime 的特权,是需要链接器配合完成的,再来看看 gobuf 在 runtime 中的 struct 定义开头部分的注释:
// The offsets of sp, pc, and g are known to (hard-coded in) libmach.
对于我们而言,这种写法读起来比较容易。
这一段执行完之后,就把 m0,g0,m.tls[0] 串联起来了。通过 m.tls[0] 可以找到 g0,通过 g0 可以找到 m0(通过 g 结构体的 m 字段)。并且,通过 m 的字段 g0,m0 也可以找到 g0。于是,主线程和 m0,g0 就关联起来了。
从这里还可以看到,保存在主线程本地存储中的值是 g0 的地址,也就是说工作线程的私有全局变量其实是一个指向 g 的指针而不是指向 m 的指针。
目前这个指针指向g0,表示代码正运行在 g0 栈。
于是,前面的图又增加了新的玩伴 m0:

初始化 m0
MOVL 16(SP), AX // copy argc
MOVL AX, 0(SP)
MOVQ 24(SP), AX // copy argv
MOVQ AX, 8(SP)
CALL runtime·args(SB)
// 初始化系统核心数
CALL runtime·osinit(SB)
// 调度器初始化
CALL runtime·schedinit(SB)
L1-L2 将 16(SP) 处的内容移动到 0(SP),也就是栈顶,通过前面的图,16(SP) 处的内容为 argc;L3-L4 将 argv 存入 8(SP),接下来调用 runtime·args 函数,处理命令行参数。
接着,连续调用了两个 runtime 函数。osinit 函数初始化系统核心数,将全局变量 ncpu 初始化的核心数,schedinit 则是本文的核心:调度器的初始化。
下面,我们来重点看 schedinit 函数:
// src/runtime/proc.go
// The bootstrap sequence is:
//
// call osinit
// call schedinit
// make & queue new G
// call runtime·mstart
//
// The new G calls runtime·main.
func schedinit() {
// getg 由编译器实现
// get_tls(CX)
// MOVQ g(CX), BX; BX存器里面现在放的是当前g结构体对象的地址
_g_ := getg()
if raceenabled {
_g_.racectx, raceprocctx0 = raceinit()
}
// 最多启动 10000 个工作线程
sched.maxmcount = 10000
tracebackinit()
moduledataverify()
// 初始化栈空间复用管理链表
stackinit()
mallocinit()
// 初始化 m0
mcommoninit(_g_.m)
alginit() // maps must not be used before this call
modulesinit() // provides activeModules
typelinksinit() // uses maps, activeModules
itabsinit() // uses activeModules
msigsave(_g_.m)
initSigmask = _g_.m.sigmask
goargs()
goenvs()
parsedebugvars()
gcinit()
sched.lastpoll = uint64(nanotime())
// 初始化 P 的个数
// 系统中有多少核,就创建和初始化多少个 p 结构体对象
procs := ncpu
if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 {
procs = n
}
if procs > _MaxGomaxprocs {
procs = _MaxGomaxprocs
}
// 初始化所有的 P,正常情况下不会返回有本地任务的 P
if procresize(procs) != nil {
throw("unknown runnable goroutine during bootstrap")
}
// ……………………
}
这个函数开头的注释很贴心地把 Go 程序初始化的过程又说了一遍:
- call osinit。初始化系统核心数。
- call schedinit。初始化调度器。
- make & queue new G。创建新的 goroutine。
- call runtime·mstart。调用 mstart,启动调度。
- The new G calls runtime·main。在新的 goroutine 上运行 runtime.main 函数。
函数首先调用 getg() 函数获取当前正在运行的 g,getg() 在 src/runtime/stubs.go 中声明,真正的代码由编译器生成。
// getg returns the pointer to the current g.
// The compiler rewrites calls to this function into instructions
// that fetch the g directly (from TLS or from the dedicated register).
func getg() *g
注释里也说了,getg 返回当前正在运行的 goroutine 的指针,它会从 tls 里取出 tls[0],也就是当前运行的 goroutine 的地址。编译器插入类似下面的代码:
get_tls(CX)
MOVQ g(CX), BX; // BX存器里面现在放的是当前g结构体对象的地址
继续往下看:
sched.maxmcount = 10000
设置最多只能创建 10000 个工作线程。
然后,调用了一堆 init 函数,初始化各种配置,现在不去深究。只关心本小节的重点,m0 的初始化:
// 初始化 m
func mcommoninit(mp *m) {
// 初始化过程中_g_ = g0
_g_ := getg()
// g0 stack won't make sense for user (and is not necessary unwindable).
if _g_ != _g_.m.g0 {
callers(1, mp.createstack[:])
}
// random 初始化
mp.fastrand = 0x49f6428a + uint32(mp.id) + uint32(cputicks())
if mp.fastrand == 0 {
mp.fastrand = 0x49f6428a
}
lock(&sched.lock)
// 设置 m 的 id
mp.id = sched.mcount
sched.mcount++
// 检查已创建系统线程是否超过了数量限制(10000)
checkmcount()
// ………………省略了初始化 gsignal
// Add to allm so garbage collector doesn't free g->m
// when it is just in a register or thread-local storage.
mp.alllink = allm
atomicstorep(unsafe.Pointer(&allm), unsafe.Pointer(mp))
unlock(&sched.lock)
// ………………
}
因为 sched 是一个全局变量,多个线程同时操作 sched 会有并发问题,因此先要加锁,操作结束之后再解锁。
mp.id = sched.mcount
sched.mcount++
checkmcount()
可以看到,m0 的 id 是 0,并且之后创建的 m 的 id 是递增的。checkmcount() 函数检查已创建系统线程是否超过了数量限制(10000)。
mp.alllink = allm
将 m 挂到全局变量 allm 上,allm 是一个指向 m 的的指针。
atomicstorep(unsafe.Pointer(&allm), unsafe.Pointer(mp))
这一行将 allm 变成 m 的地址,这样变成了一个循环链表。之后再新建 m 的时候,新 m 的 alllink 就会指向本次的 m,最后 allm 又会指向新创建的 m。

上图中,1 将 m0 挂在 allm 上。之后,若新创建 m,则 m1 会和 m0 相连。
完成这些操作后,大功告成!解锁。
初始化 allp
跳过一些其他的初始化代码,继续往后看:
procs := ncpu
if n, ok := atoi32(gogetenv("GOMAXPROCS")); ok && n > 0 {
procs = n
}
if procs > _MaxGomaxprocs {
procs = _MaxGomaxprocs
}
这里就是设置 procs,它决定创建 P 的数量。ncpu 这里已经被赋上了系统的核心数,因此代码里不设置 GOMAXPROCS 也是没问题的。这里还限制了 procs 的最大值,为 1024。
来看最后一个核心的函数:
// src/runtime/proc.go
func procresize(nprocs int32) *p {
old := gomaxprocs
if old < 0 || old > _MaxGomaxprocs || nprocs <= 0 || nprocs > _MaxGomaxprocs {
throw("procresize: invalid arg")
}
// ……………………
// update statistics
// 更新数据
now := nanotime()
if sched.procresizetime != 0 {
sched.totaltime += int64(old) * (now - sched.procresizetime)
}
sched.procresizetime = now
// 初始化所有的 P
for i := int32(0); i < nprocs; i++ {
pp := allp[i]
if pp == nil {
// 申请新对象
pp = new(p)
pp.id = i
// pp 的初始状态为 stop
pp.status = _Pgcstop
pp.sudogcache = pp.sudogbuf[:0]
for i := range pp.deferpool {
pp.deferpool[i] = pp.deferpoolbuf[i][:0]
}
// 将 pp 存放到 allp 处
atomicstorep(unsafe.Pointer(&allp[i]), unsafe.Pointer(pp))
}
// ……………………
}
// 释放多余的 P。由于减少了旧的 procs 的数量,因此需要释放
// ……………………
// 获取当前正在运行的 g 指针,初始化时 _g_ = g0
_g_ := getg()
if _g_.m.p != 0 && _g_.m.p.ptr().id < nprocs {
// continue to use the current P
// 继续使用当前 P
_g_.m.p.ptr().status = _Prunning
} else {
// 初始化时执行这个分支
// ……………………
_g_.m.p = 0
_g_.m.mcache = nil
// 取出第 0 号 p
p := allp[0]
p.m = 0
p.status = _Pidle
// 将 p0 和 m0 关联起来
acquirep(p)
if trace.enabled {
traceGoStart()
}
}
var runnablePs *p
// 下面这个 for 循环把所有空闲的 p 放入空闲链表
for i := nprocs - 1; i >= 0; i-- {
p := allp[i]
// allp[0] 跟 m0 关联了,不会进行之后的“放入空闲链表”
if _g_.m.p.ptr() == p {
continue
}
// 状态转为 idle
p.status = _Pidle
// p 的 LRQ 里没有 G
if runqempty(p) {
// 放入全局空闲链表
pidleput(p)
} else {
p.m.set(mget())
p.link.set(runnablePs)
runnablePs = p
}
}
stealOrder.reset(uint32(nprocs))
var int32p *int32 = &gomaxprocs // make compiler check that gomaxprocs is an int32
atomic.Store((*uint32)(unsafe.Pointer(int32p)), uint32(nprocs))
// 返回有本地任务的 P 链表
return runnablePs
}
代码比较长,这个函数不仅是初始化的时候会执行到,在中途改变 procs 的值的时候,仍然会调用它。所有存在很多一般不用关心的代码,因为一般不会在中途重新设置 procs 的值。我把初始化无关的代码删掉了,这样会更清晰一些。
函数先是从堆上创建了 nproc 个 P,并且把 P 的状态设置为 _Pgcstop,现在全局变量 allp 里就维护了所有的 P。
接着,调用函数 acquirep 将 p0 和 m0 关联起来。我们来详细看一下:
func acquirep(_p_ *p) {
// Do the part that isn't allowed to have write barriers.
acquirep1(_p_)
// have p; write barriers now allowed
_g_ := getg()
_g_.m.mcache = _p_.mcache
// ……………………
}
先调用 acquirep1 函数真正地进行关联,之后,将 p0 的 mcache 资源赋给 m0。再来看 acquirep1:
func acquirep1(_p_ *p) {
_g_ := getg()
// ……………………
_g_.m.p.set(_p_)
_p_.m.set(_g_.m)
_p_.status = _Prunning
}
可以看到就是一些字段相互设置,执行完成后:
g0.m.p = p0
p0.m = m0
并且,p0 的状态变成了 _Prunning。
接下来是一个循环,它将除了 p0 的所有非空闲的 P,放入 P 链表 runnablePs,并返回给 procresize 函数的调用者,并由调用者来“调度”这些 P。
函数 runqempty 用来判断一个 P 是否是空闲,依据是 P 的本地 run queue 队列里有没有 runnable 的 G,如果没有,那 P 就是空闲的。
// src/runtime/proc.go
// 如果 _p_ 的本地队列里没有待运行的 G,则返回 true
func runqempty(_p_ *p) bool {
// 这里涉及到一些数据竞争,并不是简单地判断 runqhead == runqtail 并且 runqnext == nil 就可以
//
for {
head := atomic.Load(&_p_.runqhead)
tail := atomic.Load(&_p_.runqtail)
runnext := atomic.Loaduintptr((*uintptr)(unsafe.Pointer(&_p_.runnext)))
if tail == atomic.Load(&_p_.runqtail) {
return head == tail && runnext == 0
}
}
}
并不是简单地判断 head == tail 并且 runnext == nil 为真,就可以说明 runq 是空的。因为涉及到一些数据竞争,例如在比较 head == tail 时为真,但此时 runnext 上其实有一个 G,之后再去比较 runnext == nil 的时候,这个 G 又通过 runqput跑到了 runq 里去了或者通过 runqget 拿走了,runnext 也为真,于是函数就判断这个 P 是空闲的,这就会形成误判。
因此 runqempty 函数先是通过原子操作取出了 head,tail,runnext,然后再次确认 tail 没有发生变化,最后再比较 head == tail 以及 runnext == nil,保证了在观察三者都是在“同时”观察到的,因此,返回的结果就是正确的。
说明一下,runnext 上有时会绑定一个 G,这个 G 是被当前 G 唤醒的,相比其他 G 有更高的执行优先级,因此把它单独拿出来。
函数的最后,初始化了一个“随机分配器”:
stealOrder.reset(uint32(nprocs))
将来有些 m 去偷工作的时候,会遍历所有的 P,这时为了偷地随机一些,就会用到 stealOrder 来返回一个随机选择的 P,后面的文章会再讲。
这样,整个 procresize 函数就讲完了,这也意味着,调度器的初始化工作已经完成了。
还是引用阿波张公号文章里的总结,写得太好了,很简洁,很难再优化了:
- 使用 make([]*p, nprocs) 初始化全局变量 allp,即 allp = make([]*p, nprocs)
- 循环创建并初始化 nprocs 个 p 结构体对象并依次保存在 allp 切片之中
- 把 m0 和 allp[0] 绑定在一起,即 m0.p = allp[0],allp[0].m = m0
- 把除了 allp[0] 之外的所有 p 放入到全局变量 sched 的 pidle 空闲队列之中
说明一下,最后一步,代码里是将所有空闲的 P 放入到调度器的全局空闲队列;对于非空闲的 P(本地队列里有 G 待执行),则是生成一个 P 链表,返回给 procresize 函数的调用者。
最后我们将 allp 和 allm 都添加到图上:

参考资料
【阿波张 goroutine 调度器初始化】https://mp.weixin.qq.com/s/W9D4Sl-6jYfcpczzdPfByQ